
Let’s be frank - if you aren’t already implementing Search Engine Optimization (SEO) in your marketing strategy, you should be.
Optimizing your site for organic search can bring a lot of value to your business by bringing you quality visitors and engaged users. Though Google and other search engines are placing more and more importance on the value and relevance of your content, SEO is about more than just that. If you think you have already mastered the art of creating killer content that resonates with your audience, it’s time to take a step back and take a look at your technical SEO. Even the most talented content creators can get tripped up by technical issues.
In this article, we’ll show you how to find and fix those supertechnical issues that could be stopping your site from reaching its full search potential.

Robots.txt Files

Don’t get me wrong - having a robots.txt file is important for your SEO to make sure Google can properly crawl and index your site. There are many reasons you might not want a page or folder to be indexed.
An error (or many) in robots.txt files can be the main reason you have an SEO problem, though.
Disallowing entire servers is a common practice to combat duplicate content issues when migrating a website, but it will cause whole sites not to get indexed. So, if your recently migrated site is failing to get traffic, check your robots.txt file.
If you see this:
User-agent: *
Disallow: /
You’ve got an overzealous file that’s stopping crawlers from accessing your site entirely. You can fix it with more specific commands in your file, like certain pages, folders or file types:
User-agent: *
Disallow: /folder/copypage1.html
Disallow: /folder/duplicatepages/
Disallow: *.ppt$
If you created the original robots.txt file as a part of your site’s migration, wait until the migration is done before you let bots crawl your website.

Unintentional NoIndex Tags

The meta robots tag is complementary to the robots.txt file. It can sometimes be smart to double up and use the meta robots tag on a disallowed page. The robots.txt file won’t stop search engines from crawling a page it finds from another site’s backlink, but the meta robots tag can.
If you don’t want those pages indexed or crawled, add the meta robots “noindex” tag to pages you desperately don’t want to be indexed. The noindex tag goes in the page’s <head>:
<meta name="robots” content=”noindex”>
There are a lot of reasons to use the meta robots tag to stop a page from getting indexed. But, if your pages aren’t getting crawled, you should check this ASAP. You can find out using the site: search operator in Google.
If you have already checked the site: search operator in Google to check your number of indexed pages and it’s way, way fewer than the number of pages you actually have - it’s time for a Site Crawl.
Once you’ve launched a site crawl with an audit tool like WooRank, for example, click on the indexing section. Pages that have been disallowed via the meta robots tags will all be listed here.
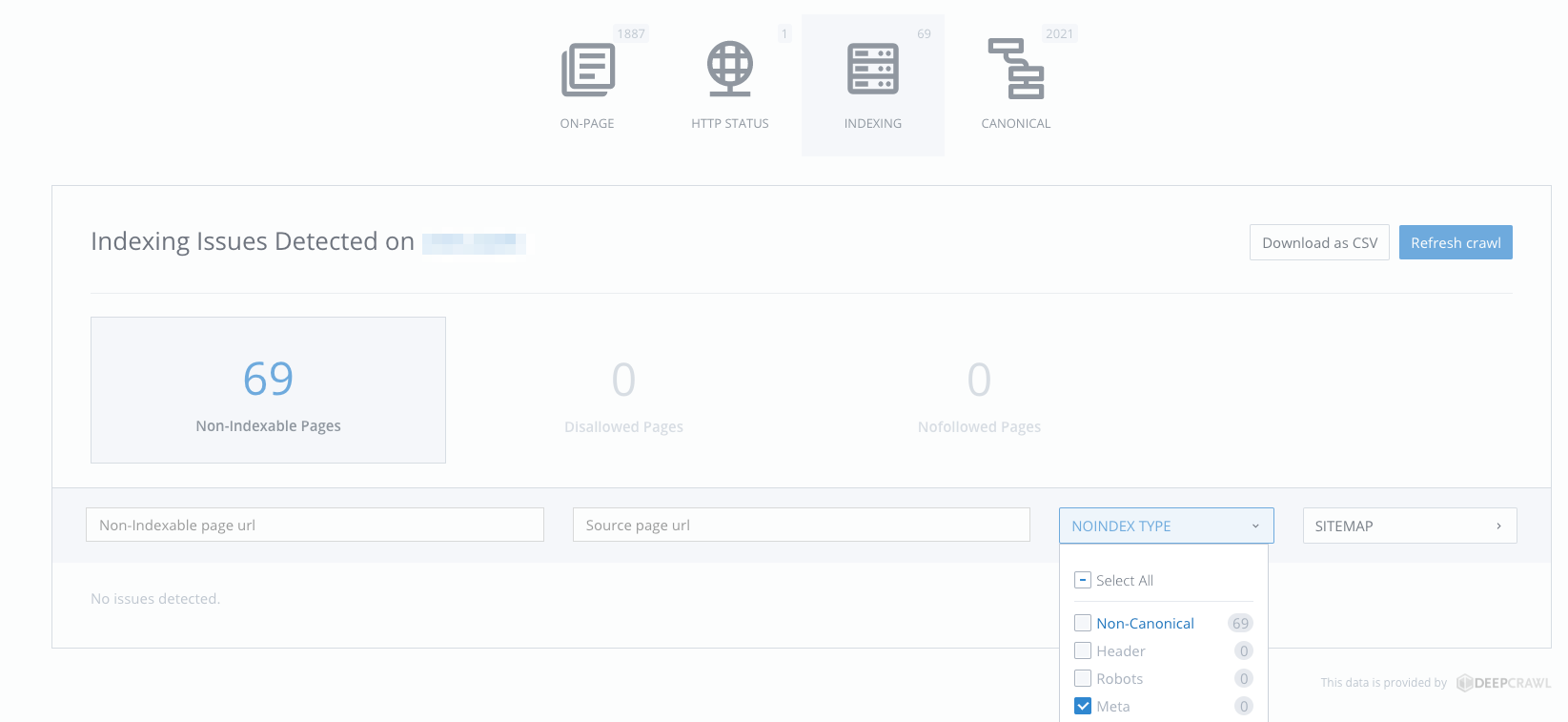
In the above example, no issues with meta robots tags were found.
Not Optimizing Redirects

Sometimes, redirects are necessary. It’s a fact of SEO life. 301s (and now 302s) allow you to move pages to new locations and keep those pages’ link juice, authority and ranking power.
It’s important to note that 301s can only help your site’s SEO if you use them in the right way. If you use them incorrectly or set them and forget them, the user experience will deteriorate right alongside your SEO.

There are four ways unoptimized redirects will hurt you:
Redirect Chains
Let’s say you have a page at www.example.com/conversion-rate-optimization that you want to move over to www.example.com/CRO. Sometime later, you decide you want to move it to www.example/com/marketing/CRO.
This is what’s known as a redirect chain. It occurs when a link points to a URL that brings you to another URL that then brings you to another URL (you get the idea). They can happen when you’ve moved a page several times.
Despite the fact that all 3xx redirects pass full link equity, it’s still not wise to pile them on top of each other. Each redirect is going to increase your page load time.
You might be thinking to yourself, do milliseconds even matter? Well, when every tenth of a second can alter your conversion rate, yea...they matter. Once you begin placing two, three, or four redirects on top of each other, we’re talking about an extra couple of seconds for the destination page to load. Hello, high bounce rate.
Again, using a crawler will help you find these redirect chains. Screaming Frog SEO Spider has a report that shows each redirect chain you are linking to.
Redirecting Internal Links
There will be cases in which it’s impossible to stop a backlink from pointing to a redirected URL. That said, there is no reason your own internal links should be doing it - you control them, after all.
These internal redirects add unnecessary load times to your pages. Google Search Console can help you find your redirected internal links under “Search Traffic”.
In Excel, use the concatenate function to place your domain in front of the URL. After you’ve done that, copy and paste those URLs into your crawler to find your internal links that return a 3xx status. Now, you have a list of internal redirects on your site - which is super easy to fix. Just update the URL.
Redirected Canonical URLs
Canonical URLs are the right URL according to your website’s canon (as the name would suggest). These are your true URLs, so the URLs listed in your site’s canonical tags shouldn’t point to a redirect.
Search engines will follow the link in a canonical tag and pass that page’s ranking attributes there. So, if a 301 redirect is added to that process, it behaves like a redirect chain; the crawler now has to go through two steps to get to its destination.
Crawl your site to put together a list of your URLs used in canonical tags. Then, crawl that list to find the URLs returning 3xx status. From there, you can update your canonical tags to point to canonical links at non-redirecting URLs.
Mismatching Canonical URLs
Having a conflicting canonical URL is another sneaky technical SEO mistake that could be negatively impacting your pages. Canonical mismatches occur when the URL used in a page’s canonical tag doesn’t match other places you should be using your canonical URL.
The two most frequent instances of this are:
-
Sitemap mismatch: When the link in the canonical tag doesn’t match the URL in your sitemap.
-
Relative links: Search engines recognize full URLs in canonical tag, so it isn’t good enough to use a file, folder or path.
When fighting duplicate content issues or making sure you are sending link juice to the right pages, canonical tags are your best friend. But, using mismatch URLs here will ruin that strategy. It will cause search engines to see lots of duplicate pages, and allow giant reservoirs of link equity to form that benefits only one page on your site.
Hreflang Return Tag Errors

The hreflang tag is used to point search engines and other crawlers to different versions of a certain page in other languages. The hreflang tag can also indicate that a page is meant for visitors in a specific country.
If you have a multilingual or international website, you should have hreflang tags on your pages.
However, there is a tricky technical mistake that is easy to make with hreflang tags, known as the “return tag error”. This occurs when Example Page A references Example Page B in an hreflang tag, but Page B doesn’t have the corresponding tag for Page B.
It would look like this for Page A:
<link rel="alternate” hreflang=”en” href=”https://www.example.com/page-A”>
<link rel="alternate” hreflang=”es” href=”https://www.example.com/page-B”>
And look like this for Page B:
<link rel="alternate” hreflang=”es” href=”https://www.example.com/page-B”>
Each version of a page has to reference every other version for hreflang to work. Note that pages also have to reference themselves. If you are missing the self-referencing tag, that’s likely the cause of hreflang return tag errors.
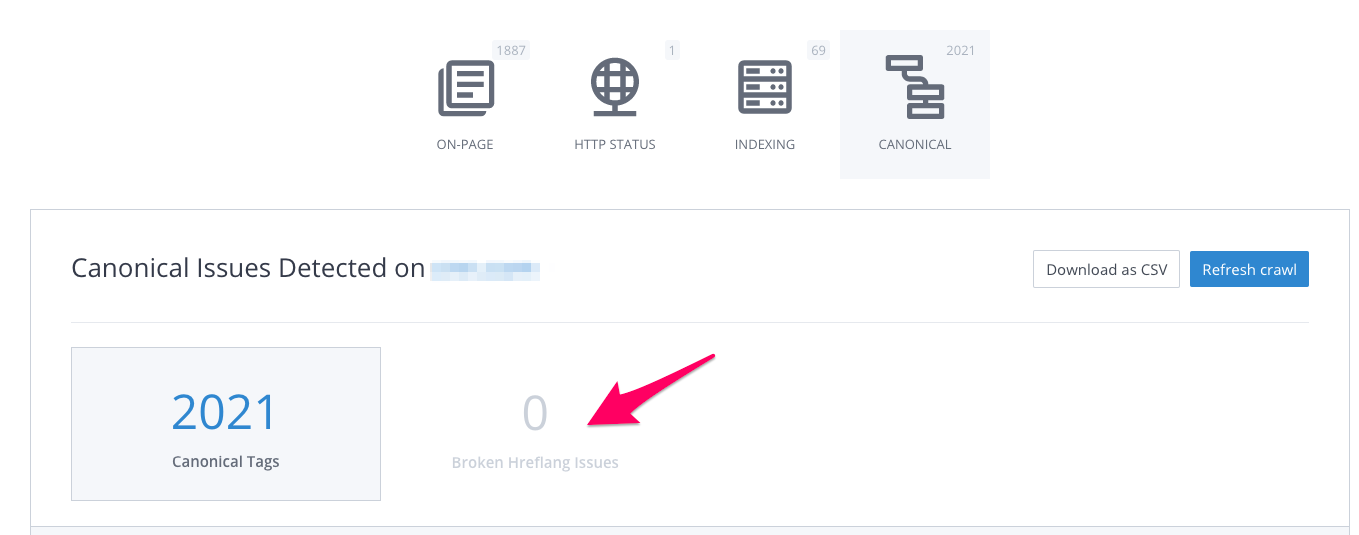
If you want to find the hreflang tags that have return errors, head to Google Search Console. Check the International Targeting report under search traffic:

For those who have used WooRank’s Site Crawl to find any of the other errors listed above, you will also discover return tag errors and other hreflang issues in the Canonical section.
Conclusion
Sidestepping these five technical SEO mistakes isn’t going to shoot your website to the top of the SERPs. Getting the number one position in Google takes a lot of on-page and off-page SEO.
However, if you fix and find (or avoid altogether) the technical errors on your site, Google will have a much easier time correctly finding, crawling and indexing your pages.
Courtney McGhee is on the Marketing Team at WooRank, an SEO audit tool that has helped millions of websites with their SEO efforts. Courtney blogs about her dog, SEO, Marketing Trends, Social Media Strategy and the Semantic Web.
Other articles worth reading:
- Inbound marketing strategy (2018)
- Why is GDPR important to marketers
- Integrate Content Marketing With Search Engine Optimisation
- Account based marketing (ABM) for life science companies
